Demystifying the GIL in Python
You spin up multiple threads in your Python code expecting blazing speed only to discover it runs just as slowly as the single-threaded version. Even worse, it sometimes performs worse. You check your CPU usage, and it’s as chilled as ever, barely breaking a sweat. What gives?
The Global Interpreter Lock (GIL) is a mutex in CPython (the default and most widely-used Python implementation). It ensures that only one thread holds the Python interpreter and executes bytecode(.pyc) at a time, even on multi-core systems.
Why would the team do such a thing? 😔
The Villain Origin Story
CPython uses a memory management technique called reference counting. Every Python object keeps track of how many references point to it. When that count reaches zero, CPython knows the object can be safely destroyed and its memory is freed.
Now, imagine a multithreaded scenario where two threads try to update an object’s reference count at the same time. One thread is increasing the count while the other decreases it or the count drops to zero prematurely while other threads still hold references. Such race conditions can lead to:
- Premature object deletion
- Memory corruption
- Program crashes
Now, because CPython's core data structures are not inherently thread-safe, to prevent these concurrency issues, it introduced the GIL, which ensures only one thread accesses the interpreter and executes at a time.
A Quick Example
import threading
shared_dict = {}
def update_dict(thread_id):
for i in range(1000):
shared_dict[i] = thread_id
threads = []
for t_id in range(3):
thread = threading.Thread(target=update_dict, args=(t_id,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
for i in range(10):
print(f"Key: {i}, Value: {shared_dict[i]}\n")
Each of the 3 threads is writing its thread_id to the dictionary keys. In a perfect world:
Thread 0 writes shared_dict[0] = 0, ..., shared_dict[9] = 0Thread 1 writes shared_dict[0] = 1, ..., shared_dict[9] = 1Thread 2 writes shared_dict[0] = 2, ..., shared_dict[9] = 2
But because they're writing concurrently, the results are unpredictable:
Key: 0, Value: 2
Key: 1, Value: 1
Key: 2, Value: 1
Key: 3, Value: 1
Key: 4, Value: 1
Key: 5, Value: 2
Key: 6, Value: 2
Key: 7, Value: 2
Key: 8, Value: 1
Key: 9, Value: 0
Hence, the GIL prevents such inconsistencies by allowing only one thread to run Python code at a time, thus preventing the abomination seen earlier
You must then be wondering, "with the GIL, what's the catch?"
The Catch: GIL and CPU-Bound Tasks
The GIL becomes a major bottleneck for CPU-bound tasks.
Even if you run a multi-core system, only one thread can execute Python bytecode at a time. So parallelism is... well, fake. Threads just take turns instead of working in true parallel.
However, for I/O-bound tasks (like reading files, Network calls, or talking to databases), the GIL is less of a problem. When a thread performs I/O, it usually releases the GIL allowing other threads to do work, hence multithreading is still beneficial for I/O-bound tasks.
Now I guess you're asking again, is there a workaround?
So How Do You Work Around the GIL?
-
Multiprocessing
The multiprocessng module is a common way to sidestep the GIL by spawning seperate processes. Each process then has it's own interpreter and GIL, enabling true parallelism across CPU cores.
But... don't get too excited, it's not free lunch
👎 Limitations of Multiprocessing
-
VCPU limits: Most machines only have 4-18 CPU cores, so there's a physical hardware limit to how much we can parallelize
-
Expensive process creation and tear down: Spawning a new process consumes significantly more resources than creating a new thread (Imagine copying the parent's memory space and setting up a new interpreter each time. Even if you used copy-on-write, it still incurs some overhead when pages are modified). This overhead outweighs whatever be benefits could have been derived from parallelism.
-
IPC Overhead: Sharing data between processes requires serialization (pickling) and deserialization (unpickling), which is slow and not always possible (Not all python objects can be pickled)
Pickling is the process of converting python object into bytestream and the reverse is unpickling
🔄 IPC Overhead 1 (Pickling Problems)
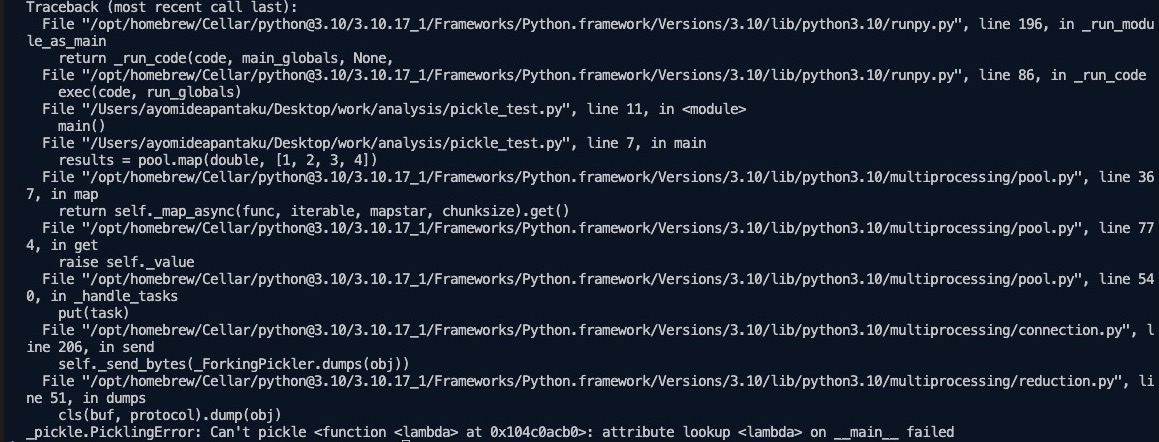
Some Python objects can't be pickled—like lambdas, file handles, generators, and thread locks.
import multiprocessing
double = lambda x: x * 2
def main():
with multiprocessing.Pool() as pool:
results = pool.map(double, [1, 2, 3, 4])
print(results)
if __name__ == "__main__":
main()
The code above raises an error because lambda functions can't be pickled:
IPC Overhead 2 (🤯 Synchronization Overhead) If you decide to use a shared memory for IPC, you'll need to manually synchronize access to shared resources or ensure proper ordering of operations using semaphores or locks, which adds complexity and potential for concurrency bugs (This could make you shave your head 😂 💀)
In summary, multiprocessing is a powerful tool for achieving parallelism especially for CPU bound tasks but its effectiveness totally depends on the nature of problem of you're trying to solve.
-
Asyncio (for I/O-bound Workloads)
asyncio module uses cooperative multitasking using async/await. It avoids the GIL entirely it still executes Python code under the GIL, it just works with it by using a single-threaded, cooperative concurrency model, where tasks yield control explicitly (using await) when they are idle or waiting on I/O, hence there's no contention for the GIL like in multithreaded programs. This makes it efficient for I/O-bound workloads
Since it’s not hindered by thread switching or context overhead, it's ideal for I/O-heavy applications.
I’ll cover asyncio in a separate post. Stay tuned 😄
-
Alternative Python Interpreters
Some Python runtimes like Jython and IronPython don't have GIL and can achieve true multithreading however, they don't support many popular python libraries.